Existing field-based approaches are constrained by the resolution of the grid which models the deformation field, the capacity of the model, or the frequencies of the input. As a result, the existing study does not properly represent complex dynamic scenes (left), and even introducing an additional feature grid that is twice the maximum resolution has only a slight improvement in performance (middle). Instead of using field representation, our model solves this problem by employing per-Gaussian latent embeddings to predict deformation for each Gaussian and achieves a clearer representation of dynamic motion (right).
Abstract
As 3D Gaussian Splatting (3DGS) provides fast and high-quality novel view synthesis, it is a natural extension to deform a canonical 3DGS to multiple frames for representing a dynamic scene. However, previous works fail to accurately reconstruct complex dynamic scenes. We attribute the failure to the design of the deformation field, which is built as a coordinate-based function. This approach is problematic because 3DGS is a mixture of multiple fields centered at the Gaussians, not just a single coordinate-based framework. To resolve this problem, we define the deformation as a function of per-Gaussian embeddings and temporal embeddings. Moreover, we decompose deformations as coarse and fine deformations to model slow and fast movements, respectively. Also, we introduce a local smoothness regularization for per-Gaussian embedding to improve the details in dynamic regions.
Overview
Existing coordinate-based network methods struggle to represent complex dynamic scenes.
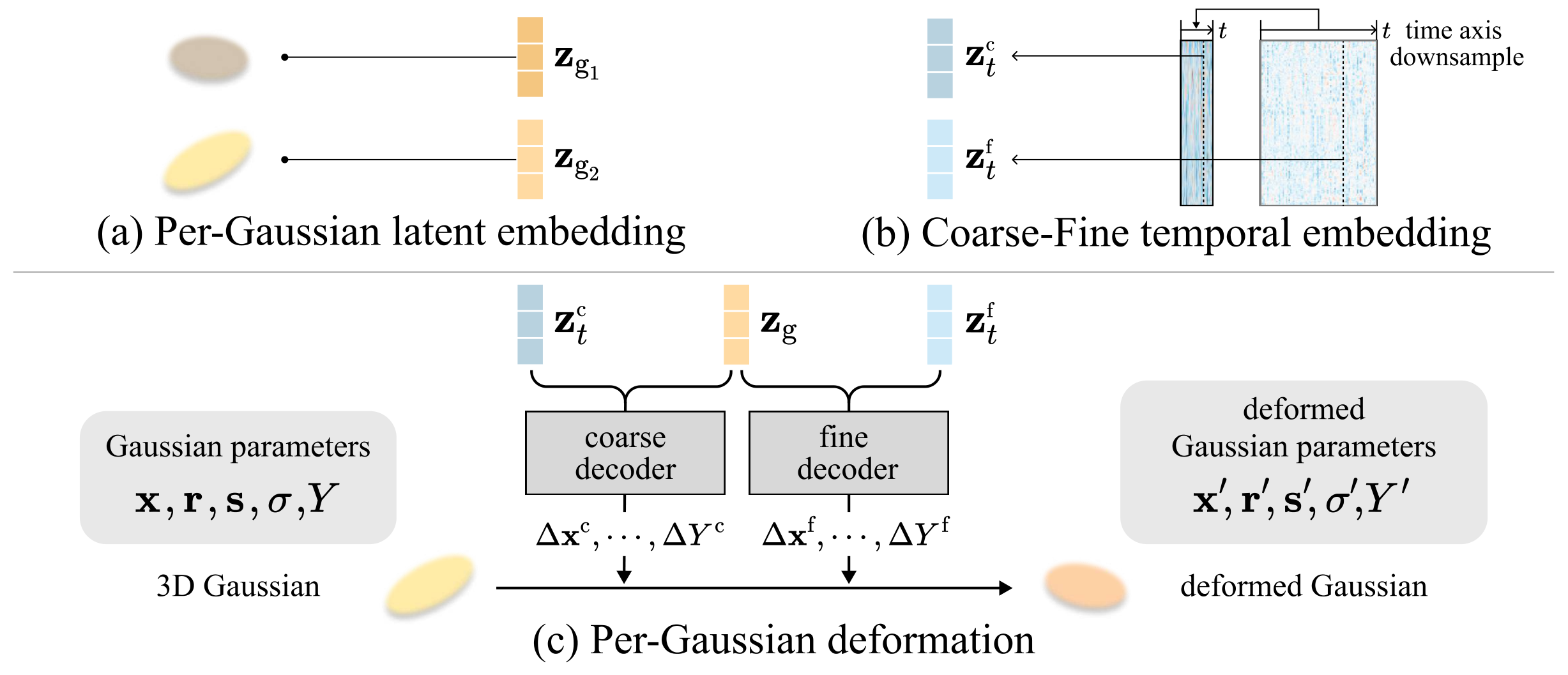
To this end, we define per-Gaussian deformation.
(a) Firstly, we assign a latent embedding for each Gaussian. Additionally, we introduce coarse and fine temporal embeddings to represent the slow and fast state of the dynamic scene.
(b) By employing two decoders that take per-Gaussian latent embeddings along with coarse and fine temporal embeddings as input, we estimate slow or large changes and fast or detailed changes to model the final deformation, respectively.
(c) Finally, we introduce a local smoothness regularization so that the embeddings of neighboring Gaussians are similar.
Rendered Results
We show the rendered results on three datasets:
Neural 3D Video, Technicolor Light Field, and HyperNeRF.

Our approach achieves high-quality rendering while effectively modeling complex dynamic changes.
Refer to the paper for the entire results of all baselines.
Put the mouse cursor to the videos below to zoom in.
Results on Neural 3D Video Dataset
Results on Technicolor Light Field Dataset
Results on HyperNeRF Dataset
Analysis
Visualization of the deformation components
Our corse-fine deformation consists of two decoders, each in charge of coarse and fine deformation.
The video above is the result of rendering each deformation removed from the trained model.
(a) When both deformations are removed, rendering yields an image in canonical space.
(b) Coarse deformation handles large or slow changes, producing results similar to the full rendering.
(c) Fine deformation handles fast or detailed changes, yielding rendering similar to canonical space.
(d) Rendering results come from applying both coarse and fine deformations to the canonical space.
Visualization of the magnitude of deformation
We visualize the magnitude of position changes in the deformation of Gaussian parameters. Coarse deformation (blue) captures large and slow changes, such as the movement of the head and torso, while fine deformation (red) is responsible for fast and detailed changes of arms, tongs, shadows, etc.